
Trust, But Verify: Can AI Replace a Peer Reviewer?
The editorial team of Consortium PSYCHIATRICUM conducted an experiment to see how ChatGPT and DeepSeek handle article peer review: we compared human reviewer assessments with those from AI. The result

Artificial intelligence has ceased to be a technology of the future — it has become a tool of the present, penetrating even strictly regulated domains such as scientific publishing. Today, many researchers already use AI assistants for translation or stylistic improvement of text, followed by human verification. This has become the new norm.

But if AI can “polish” an article, is it ready to evaluate its substance? Can an algorithm replace a human reviewer — an independent arbiter whose decision determines the fate of a scientific work?
Peer Review: A New Reality
A 2024 study analyzed reviews for articles submitted to major machine learning conferences after the release of ChatGPT’s first version. The findings indicated that between 6% and 17% of texts contained traces of AI use.
In 2025, publisher Wiley surveyed nearly five thousand researchers from 70 countries on whether they use AI tools for scientific work—including for writing reviews. According to the results, 19% of respondents used neural networks for such purposes.
What Do Scientists Think?
We decided to find out the opinion not of the global community at large, but of our professional audience — the researchers and practitioners who read the Consortium PSYCHIATRICUM Telegram channel.
45 people participated in our poll. When asked “What is your opinion on the use of AI in peer reviewing scientific articles?” they responded as follows:
58% of respondents believe a compromise is necessary. They are willing to use AI only with clear rules and limitations.
20% of respondents are exclusively in favor of using AI. They are confident that AI is a useful tool that should not be abandoned under any circumstances.
7% of respondents are categorically against any use of AI.
15% of respondents are currently undecided.
The majority favored a compromise. But what does “clear rules and limitations” mean in practice? To find out, we need only test it ourselves to see where AI excels and where the dangers of its use lie.
Armed with these insights, the journal’s editorial team decided to run an experiment: compare reviews written by human and by AI for the same article.
The Experiment: Text, Expert, and Two AIs
For the experiment, we used the initial draft of a manuscript already published in the journal to avoid breaching data confidentiality.
We took the review from a leading expert in the relevant field as our benchmark. We additionally checked their text using Pangram service for potential AI use: the system detected no traces of artificial intelligence. Two popular, freely accessible models were chosen as the “digital reviewers”: DeepSeek and ChatGPT.
First, we compared the reviews based on key parameters (topicality, novelty, originality, practical significance, scientific value, ethics, clarity of presentation, methodology, statistical analysis) and decisions. Then we compared the depth and focus of the critique — what each reviewer noticed and what they missed.
We uploaded the manuscript text and an empty review form into the neural networks, requesting an evaluation based on the given criteria. The prompt (AI query) was crafted so the neural network would act as a strict reviewer: we asked it to assess the manuscript on all parameters — from topicality and novelty to methodology and statistics — and based on that analysis, provide a detailed final recommendation.
This approach yielded a structured assessment from the AI that could be compared with the human verdict, helping us understand how well algorithms can meaningfully work with the formalized criteria of scientific expertise.
Topicality
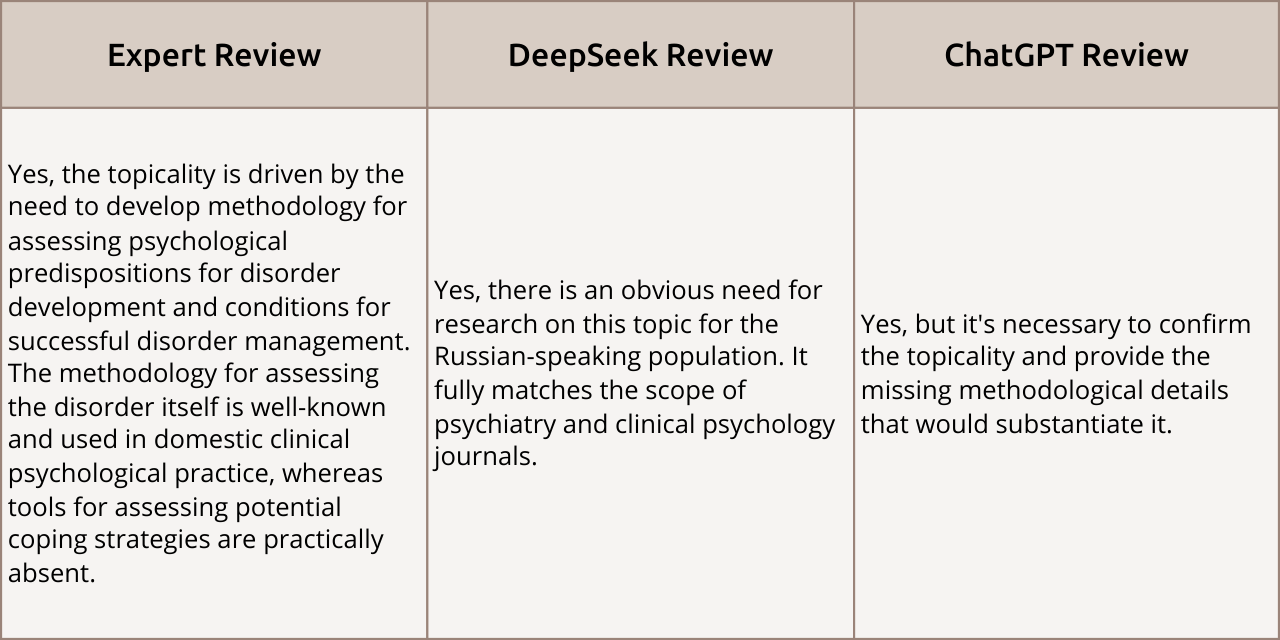
Review Comparison: The opinions of all three experts aligned: the work was deemed topical. However, ChatGPT agreed but gave a more cautious assessment, suggesting that the authors needed to further argue and confirm the topic’s relevance within the text.
Novelty
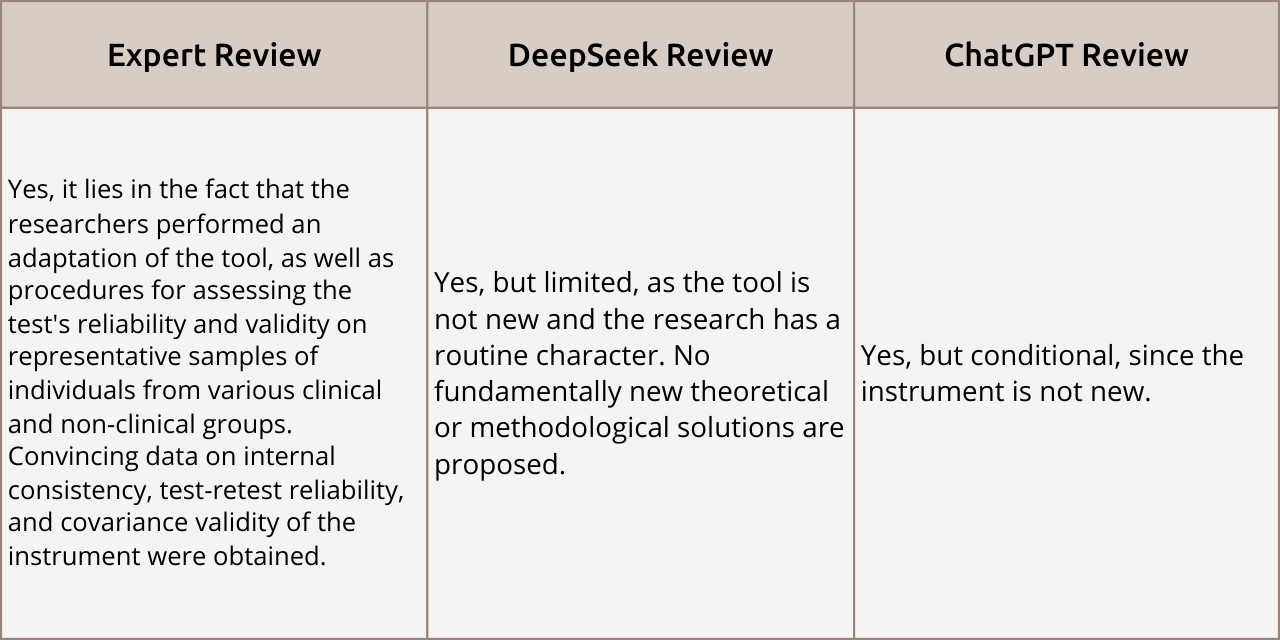
Review Comparison: The expert rated the scientific novelty highly, emphasizing the significance of the methodology adaptation. Both AI reviewers acknowledged the novelty as limited, pointing to the “routine” nature of the research since the tool itself is not new. Thus, the AI assesses global novelty, while the expert focuses on practical methodological contribution.
Originality
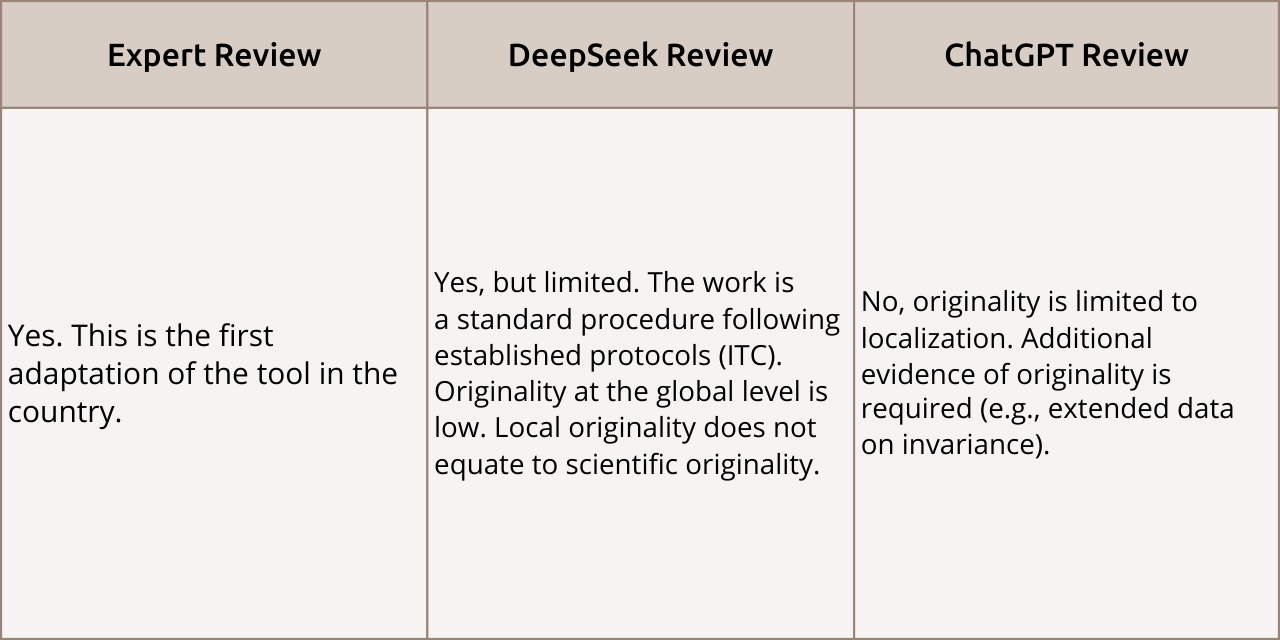
Review Comparison: Opinions on the “Originality” criterion diverged sharply. The expert highly valued the tool adaptation as the first in the country. Both AI reviewers considered the novelty limited, stating that the work is routine and does not offer global breakthroughs.
Practical Significance
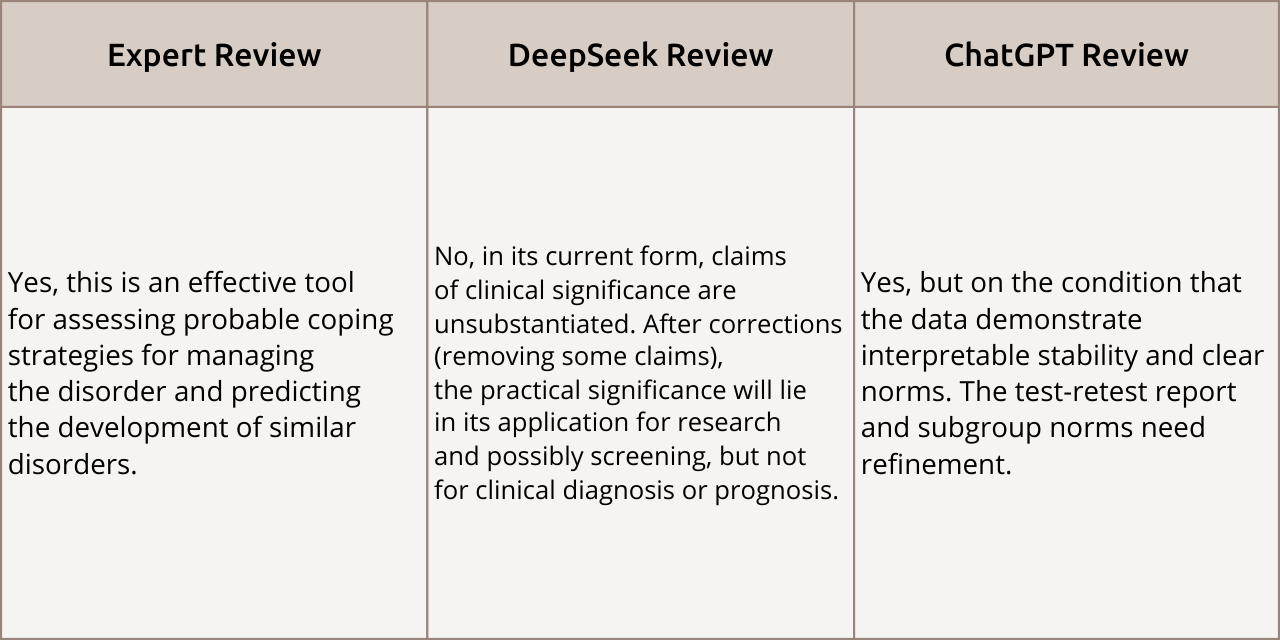
Review Comparison: The expert unequivocally recognized the tool as effective for clinical prediction. ChatGPT agreed but made it conditional on refining methodological reports. DeepSeek took a hardline skeptical stance, stating that conclusions about clinical significance in the current form were unsubstantiated. It only allowed for the method’s use in research, not for direct clinical diagnosis.
Scientific Value
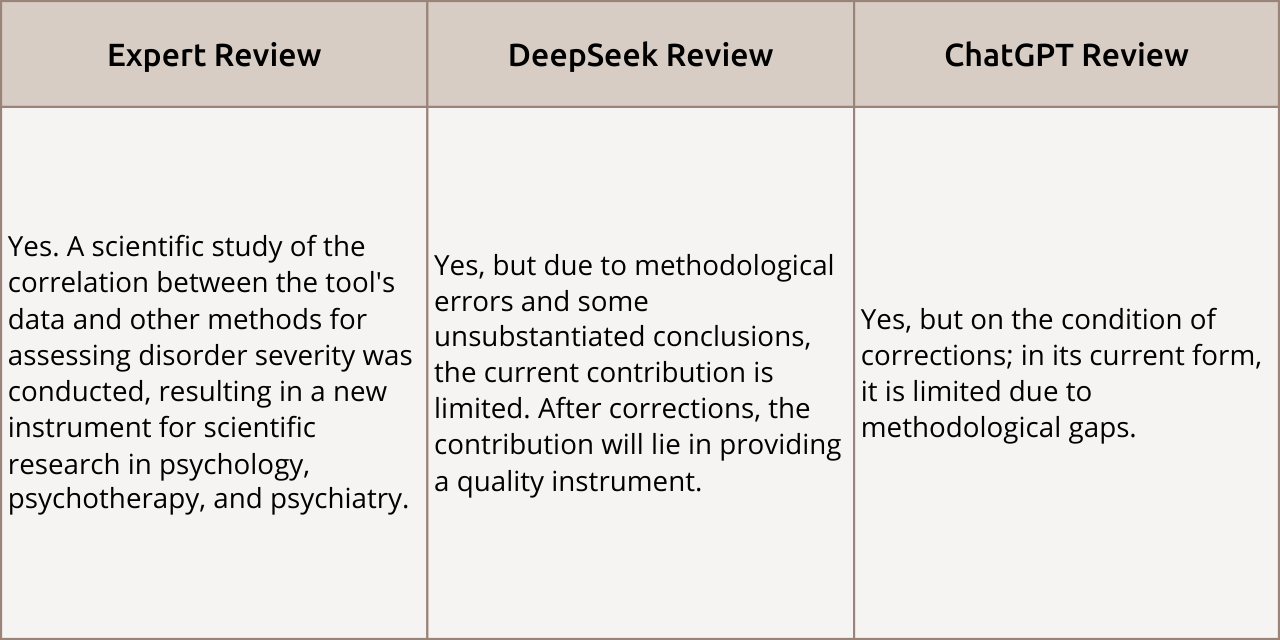
Review Comparison: All three reviewers acknowledged the work’s scientific value. However, the AI reviewers set fundamental conditions: they demanded corrections for methodological errors and unsubstantiated conclusions. Unlike the expert, who emphasized the unconditional novelty of the tool, the neural networks linked the article’s scientific value exclusively to the quality of its revision.
Publishing Ethics
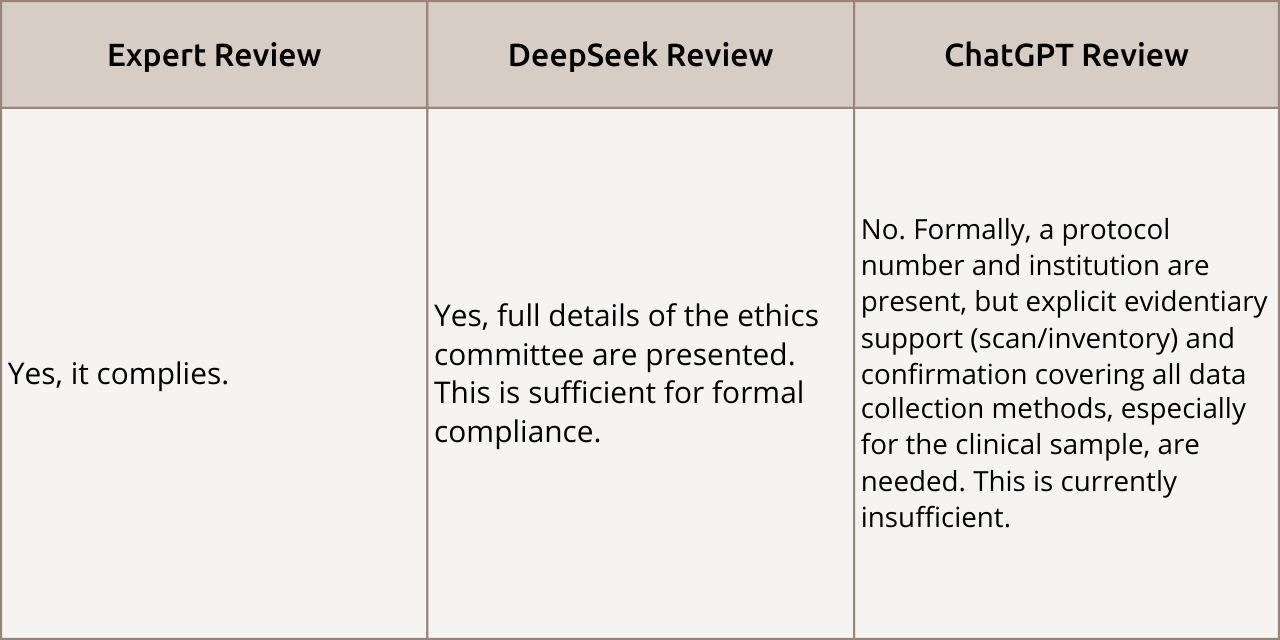
Review Comparison: The question of ethics compliance elicited formal agreement from the expert and DeepSeek, but a more detailed check from ChatGPT. The expert and DeepSeek agreed that the presented ethics committee details were sufficient. However, ChatGPT adopted a strict auditing stance, stating that a formal protocol number was insufficient and demanding scanned documents and confirmation of proper data collection.
Clarity of Presentation
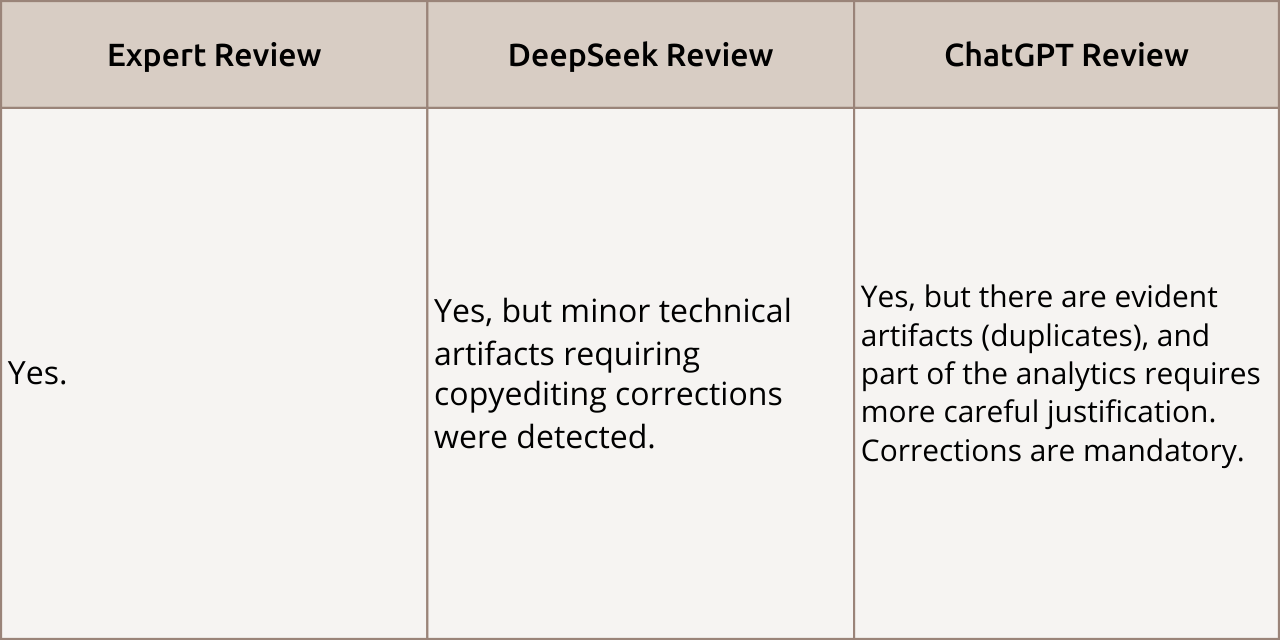
Review Comparison: A reviewer’s task does not include correcting punctuation and grammatical errors; they assess clarity of presentation itself. Nevertheless, both AIs pointed out the need for text copyediting.
General Recommendation
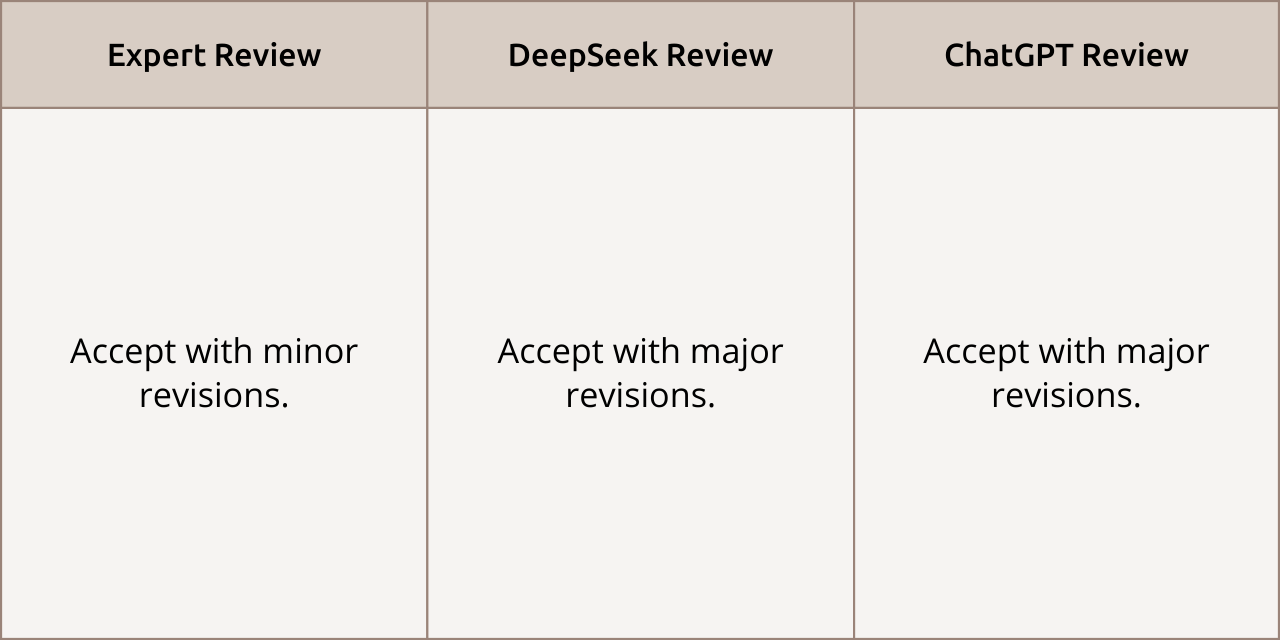
Review Comparison: All reviewers were prepared to accept the article, but the AIs believed substantial revision of the manuscript was required.
Conclusions: The Algorithm’s Blind Justice
Overall, the results were mixed. The expert’s opinion and the AI conclusions both intersected and diverged radically on some key criteria (novelty, originality, practical significance) due to different understandings of the scientific work’s essence. For example, an expert understands the context well and can therefore appreciate novelty if research is conducted “for the first time in the country,” whereas AI thinks too broadly and globally.
As a result, the AI performed as a pedantic editor, capable of quickly checking formal criteria and identifying obvious errors while remaining unbiased. However, its fundamental weaknesses—lack of understanding of scientific context, inflexibility, inability to engage in discussion, and the risk of generating contrived remarks—render it unsuitable for the full role of a scientific reviewer in the current state of neural network technology.
Not Instead, But Together: The Prospect of AI as a Reviewer’s Assistant
While the debate about AI reviewers continues on a theoretical level, the editorial team of Consortium PSYCHIATRICUM is already integrating modern technologies into the editorial process.
A tool developed by editorial board member Timur Sergeevich Syunyakov automatically checks articles against key criteria: it verifies structure against EQUATOR checklists, analyzes methodology, and checks sources for existence and citation accuracy. Authors can undergo this check before official submission to correct significant errors in advance and speed up further consideration.
The tool is available via this link.
“This is a huge resource saver for the editorial office. Moreover, AI is often more attentive to inaccuracies,” says Timur Syunyakov. “As the developer, I see that AI successfully detects even discrepancies between text and tables, which a reviewer or editor might overlook.”
According to Timur Syunyakov, the main prospect of such systems lies not in replacing the expert, but in “self-reviewing”: when researchers themselves check and edit their drafts before submission. This improves the quality of materials sent to the editorial office. After such preliminary “polishing,” editors and reviewers free up time to analyze more subtle scientific aspects beyond the algorithm’s capabilities.
The developer acknowledges the risks as well—for example, the potential leveling of individual authorial style. However, he believes the gains in accuracy and standardization are worth it.
“I am absolutely not against using AI when writing articles. Fighting it now is like tilting at windmills,” notes Timur Syunyakov. “But it’s one thing if AI is used as a tool for routine work, and another — if it’s used for fraud. Fraud is primarily detected by a human reviewer.”
This experience confirms the main conclusion of the experiment: AI cannot be the judge but becomes a valuable assistant, taking on the routine and allowing the expert to focus on the substance.
Rules of the Game: How a Scientific Journal Regulates Work with AI
A modern scientific journal’s policy must sensibly regulate the responsible use of AI by all participants in the editorial process.
What every Consortium PSYCHIATRICUM reviewer must know:
It is prohibited to upload manuscripts or reviews to public AI services, as this violates the confidentiality of materials under consideration.
It is permitted to use AI for auxiliary tasks: structuring a review outline, performing language editing on already written text, consulting on general methodological questions without disclosing details of the specific work.
It requires permission from the responsible editor for any other use of AI, especially for analyzing manuscript content.
Detailed instructions on how AI can and cannot be used can be found in the “Policy on the Use of Artificial Intelligence (AI)”.